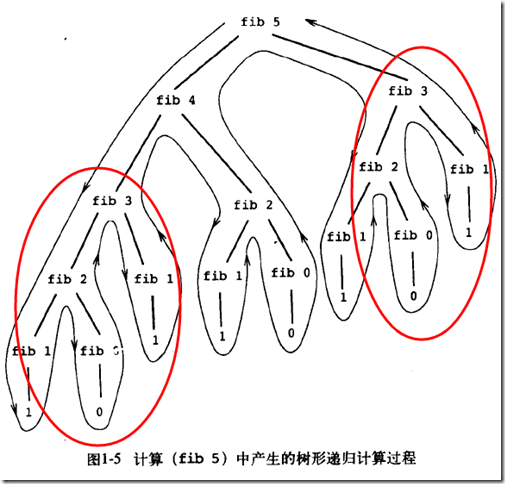
CatBoost原生接口和Sklearn接口参数详解
- LightGBM原生接口和Sklearn接口参数详解
- XGBoost原生接口和Sklearn接口参数详解
- CatBoost
- 一、Sklearn风格接口
- CatBoostRegressor参数
- CatBoostRegressor.fit参数
- CatBoostRegressor.predict参数
- 二、Catboost原生接口
- CatBoost Pool
- CatBoost可视化
- xgboost,lightgbm,catboost相同点不同点,优缺点
- 相同点:
- 不同点:
- 并行方式:
LightGBM原生接口和Sklearn接口参数详解
XGBoost原生接口和Sklearn接口参数详解
CatBoost
一、Sklearn风格接口
CatBoostRegressor参数
- iterations (int): 模型迭代次数,即构建的决策树数量。默认值是100。
- learning_rate (float): 学习率,控制模型在每一步更新权重的速度。默认值是0.03。
- depth (int): 决策树的最大深度。较高的深度可能导致过拟合,较低的深度可能欠拟合。默认值是6。
- l2_leaf_reg (float): L2正则化项的强度。较大的值会增加正则化,防止过拟合。默认值是3.0。
- loss_function (str): 用于评估模型性能的损失函数。对于回归问题,常见的选项有RMSE(均方根误差)、MAE(平均绝对误差)等。默认是RMSE。
- eval_metric (str or callable): 评估模型性能的额外指标,可以是内置的或自定义的函数。
- task_type (str): 指定任务类型,可以是CPU或GPU。若要使用GPU,需确保安装了GPU版本的CatBoost。
- devices (str): 指定要使用的GPU设备,例如’0’表示使用第一个GPU,'0,1’表示使用第一和第二个GPU。
- random_strength (float): 控制随机特征分裂的强度,用于防止过拟合。默认值是1.0。
- cat_features (list): 显式指定分类特征的索引或名称,如果数据集中有类别特征。
- border_count (int): 分类特征的边界数量,用于创建直方图。默认值是255。
- one_hot_max_size (int): 对于类别特征,如果类别数量超过这个值,将使用稀疏编码。默认值是20。
- verbose (int): 控制训练过程中的输出信息量。0表示无输出,1表示基本输出,2表示详细输出。
- early_stopping_rounds (int): 如果设置,将在验证集上监控该指标,如果在指定轮数内没有改善,则提前停止训练。
- use_best_model (bool): 是否使用验证集上表现最好的模型。默认为True。
这些参数可以在创建CatBoostRegressor实例时设置,也可以在fit方法中通过params字典传递。
CatBoostRegressor.fit参数
CatBoostRegressor.fit方法用于训练模型,它接受几个关键参数来控制训练过程和数据处理方式。以下是一些主要的参数:
- X (array-like 或 sparse matrix 或 catboost.Pool): 训练数据集的特征部分。可以是NumPy数组、pandas DataFrame、SciPy稀疏矩阵或catboost.Pool对象。
- y (array-like): 训练数据集的目标变量。对于回归任务,这应该是一个一维数组或序列。
- cat_features (list 或 None, 可选): 分类特征的列索引列表。仅当直接使用numpy数组或pandas DataFrame作为X时需要。如果使用catboost.Pool,则不需要此参数,因为分类特征已在Pool创建时指定。
- sample_weight (array-like 或 None, 可选): 样本权重数组,用于在训练过程中对不同样本赋予不同的重要性。
- group_id (array-like 或 None, 可选): 如果数据具有组结构,可以提供组ID。这在时间序列预测或需要按组进行评估时很有用。
- group_weight (array-like 或 None, 可选): 组权重,与group_id一起使用,为不同的组分配不同的权重。
- verbose (bool 或 int, 可选): 控制训练过程中的输出信息。如果是False,则不输出任何信息;如果是True或正整数,将显示训练进度。
- logging_level (str 或 int, 可选): 设置日志级别,控制输出的详细程度。
- plot (bool, 可选): 是否在Jupyter Notebook中绘制学习曲线。默认为False
- eval_set (tuple(list(array-like), array-like) 或 list(tuple(list(array-like), array-like)), 可选): 评估数据集,可以是一个元组(验证特征,验证标签)或元组列表(多个验证集)。用于监控模型在验证集上的性能,并可能触发早停。
- early_stopping_rounds (int, 可选): 当使用eval_set时,如果验证集上的性能在指定的轮数内没有提升,则停止训练。
- use_best_model (bool, 可选): 如果为True,则训练结束后返回的是在验证集上表现最好的模型。默认为True。
- verbose_eval (bool 或 int, 可选): 控制训练过程中的评估信息输出频率。如果为正整数,表示每多少轮输出一次。
- metric_period (int, 可选): 计算并输出评估指标的周期(迭代次数)。
CatBoostRegressor.predict参数
CatBoostRegressor.predict方法用于对新的数据集进行预测。该方法接受一些参数来控制预测行为。以下是一些主要的参数:
- X (array-like 或 catboost.Pool): 需要预测的目标数据集的特征部分。它可以是NumPy数组、pandas DataFrame或catboost.Pool对象。数据格式应与训练数据集中的格式相匹配。
- ntree_limit (int, 可选): 限制用于预测的树木数量。默认情况下,使用所有训练的树木。如果你只想用前n棵树进行预测,可以设置此参数。
- prediction_type (string, 可选): 预测类型。对于回归任务,默认值通常是"RawValue",意味着直接返回预测的数值。根据模型和需求,可能还有其他选项,如"Probability"(通常用于分类模型)。
- thread_count (int, 可选): 用于预测的线程数。默认情况下,CatBoost会尝试自动检测并使用所有可用的CPU核心。你可以通过设置此参数来限制使用的核心数。
- verbose (bool 或 int, 可选): 控制预测过程中的输出信息。如果为False,则不输出任何信息;如果是True或正整数,可能会显示预测进度。
二、Catboost原生接口
CatBoost Pool
-
什么是 CatBoost Pool?
CatBoost Pool 是 CatBoost 模型使用的特殊数据容器,它以优化的方式存储和处理特征数据,从而提高模型训练和预测的效率。相比于直接使用 pandas DataFrame 或 numpy array,Pool 能够更高效地处理 categorical 特征,并且支持稀疏数据表示,减少内存占用和加速计算过程。 -
为什么使用 Pool?
性能优化:Pool 对数据进行预处理,包括对类别特征的独热编码(one-hot encoding)和对缺失值的处理,这一步骤在数据加载时完成,避免了在每次迭代时重复处理。
内存效率:对于大规模数据集,Pool 支持稀疏数据格式,减少内存占用。
并行处理:Pool 设计支持并行加载数据和训练过程中的并行计算,充分利用多核CPU资源。
灵活性:可以直接指定 label、权重、基线值等,便于进行更复杂的数据处理和模型调优。 -
Pool 的特性
自动处理类别特征:CatBoost Pool 自动识别分类特征,并进行适当的编码,无需用户手动编码。
缺失值处理:支持在创建 Pool 时指定缺失值处理策略。
分块加载:对于大数据集,可以设置 chunksize 参数分块加载数据,减少内存峰值。
并行读取:通过设置 thread_count 参数,可以在创建 Pool 时利用多线程并行读取数据。
from catboost import CatBoostRegressor
# 初始化模型实例
model = CatBoostRegressor(
iterations=1000, # 训练迭代次数
learning_rate=0.03, # 学习率
depth=6, # 决策树最大深度
loss_function='RMSE', # 损失函数,回归任务常用'RMSE'
eval_metric='RMSE', # 评估指标
random_seed=42, # 随机种子,确保结果可复现
l2_leaf_reg=3, # L2正则化系数
task_type='CPU', # 训练任务类型,可选'CPU'或'GPU'
verbose=True # 输出训练过程信息
)
# 特征与标签:准备特征矩阵X和目标变量向量y。
# 分类特征处理:如果数据中含有分类特征,需要指定它们的索引或名称。
# 创建Pool对象:为了高效处理数据,尤其是大型数据集,推荐使用Pool对象。它可以处理类别特征、权重、基学习率等,并且支持稀疏数据格式。
from catboost import Pool
# 假设X_train, y_train是训练数据和标签
pool_train = Pool(data=X_train, label=y_train, cat_features=cat_features_indices)
# 可以创建验证集Pool
pool_valid = Pool(data=X_valid, label=y_valid, cat_features=cat_features_indices)
# 使用fit方法进行训练,可以传入多个Pool进行验证
model.fit(pool_train,
eval_set=pool_valid, # 验证集
early_stopping_rounds=50, # 早停策略,连续多少轮没提升就停止训练
use_best_model=True) # 是否使用验证集上最优的模型
# 对新数据进行预测
predictions = model.predict(X_test)
# 获取特征重要性
feature_importances = model.get_feature_importance(pool_train)
# 保存模型
model.save_model('model.cbm')
# 加载模型
loaded_model = CatBoostRegressor().load_model('model.cbm')
# 可以通过get_params()和set_params()方法查看和修改模型参数。
# 查看当前模型参数
params = model.get_params()
# 修改参数
model.set_params(learning_rate=0.01)
from catboost import cv
# 执行交叉验证
cv_results = cv(pool=pool_train,
params=model.get_params(),
fold_count=5, # 折叠数
stratified=False, # 是否分层采样
shuffle=True, # 是否打乱数据
partition_random_seed=42) # 分区随机种子
CatBoost允许用户定义自己的损失函数和评估指标,这需要编写相应的Python函数,并在初始化模型时指定。
- 多线程和GPU使用:通过thread_count和task_type参数控制。
- 正则化:通过l2_leaf_reg等参数进行模型复杂度控制。
- 类别特征处理:在创建Pool时指定cat_features。
CatBoost可视化
- 学习曲线可视化
在 Jupyter Notebook 中,可以使用 plot_learning_curve 函数来绘制模型的学习曲线,展示训练集和验证集的损失或评估指标随迭代次数的变化情况。这有助于分析模型是否过拟合或欠拟合。
import catboost
from catboost import CatBoostClassifier
# 训练模型
model = CatBoostClassifier(iterations=100)
model.fit(train_pool, eval_set=test_pool)
# 绘制学习曲线
model.plot_learning_curve(train_pool, test_pool)
- 特征重要性
可以使用 get_feature_importance 方法获取特征的重要性,并通过 matplotlib 等库进行可视化,展示哪些特征对模型预测贡献最大。
import matplotlib.pyplot as plt
# 获取特征重要性
importances = model.get_feature_importance(train_pool)
# 可视化特征重要性
plt.bar(range(len(importances)), importances)
plt.xlabel('Feature Index')
plt.ylabel('Importance')
plt.title('Feature Importances')
plt.show()
- 特征分析
CatBoost 支持对类别特征进行 Ordered Target Statistics 的可视化,这有助于理解特征值与目标变量之间的关系。
# 分析并可视化特定特征
feature_name = 'your_feature_name'
feature_importance_plot = model.plot_feature_importance([feature_name])
- Shap Values(SHAP解释)
虽然不是 CatBoost 直接提供的,但可以与 SHAP 库结合,生成复杂的特征贡献解释图,如 SHAP 柱状图或 SHAP 决策图。
import shap
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(test_pool.get_X())
# 可视化(例如,使用 SHAP 柱状图)
shap.summary_plot(shap_values, test_pool.get_X(), feature_names=test_pool.get_feature_names())
- TensorBoard集成
CatBoost 支持将训练过程的日志输出到 TensorBoard 格式,从而可以在 TensorBoard 中可视化更多的训练细节,如损失曲线、学习速率变化等。
# 在训练时启用 TensorBoard 日志记录
model.fit(train_pool, eval_set=test_pool, verbose=False, plot=True)
xgboost,lightgbm,catboost相同点不同点,优缺点
相同点:
梯度提升决策树(GBDT)框架:XGBoost、LightGBM、和CatBoost都是基于梯度提升决策树(Gradient Boosting Decision Tree, GBDT)的机器学习算法,通过迭代地添加决策树以逐步降低预测误差。
目标函数优化:它们都采用梯度下降方法来最小化损失函数,通过迭代过程不断优化模型。
特征重要性:都能提供特征重要性评估,帮助理解哪些特征对模型预测最为关键。
并行计算:都支持一定程度的并行计算,加快训练速度。XGBoost和LightGBM主要通过列块并行和数据并行来加速,而CatBoost则在处理类别特征时有特定的优化。
不同点:
处理类别特征:
CatBoost:自动处理类别特征,不需要用户进行独热编码,内置了对类别特征的高效处理机制。
XGBoost和LightGBM:需要用户先对类别特征进行编码处理,如独热编码。
稀疏数据处理:
LightGBM:特别优化了对稀疏数据的处理,使用了直方图算法来减少计算量,提高了效率。
XGBoost和CatBoost:虽然也能处理稀疏数据,但可能不如LightGBM高效。
训练速度:
LightGBM:通常被认为是最快的,因为它采用了直方图近似和单边梯度采样等策略减少计算量。
XGBoost:虽然也很快,但在大规模数据集上可能不如LightGBM。
CatBoost:在某些场景下,尤其是含有大量类别特征时,由于其独特的处理方式,也能表现出色。
并行方式:
XGBoost:支持并行计算,包括特征并行和数据并行。
LightGBM:主要通过数据并行和直方图算法加速。
CatBoost:除了传统的并行计算外,还针对类别特征处理进行了优化。
优点:
XGBoost:成熟稳定,社区支持广泛,提供了丰富的参数调优空间。
LightGBM:训练速度快,内存使用效率高,适合大规模数据集。
CatBoost:自动处理类别特征和缺失值,有较好的默认参数设置,适合处理含有类别特征的数据。
缺点:
XGBoost:在大规模数据集上训练速度可能不如LightGBM和CatBoost。
LightGBM:在处理含有大量类别特征的数据时可能不如CatBoost高效。
CatBoost:相比于其他两者,CatBoost的安装和使用可能稍微复杂一些,尤其是在Windows系统上。